LSS: Rolled Throughput Yield (RTY)
Gepubliceerd in
Lean Six Sigma
.jpg)
Binnen Lean Six Sigma is de Rolled Throughput Yield (RTY) een procesmetriek (metric) die staat voor de kans dat een product zonder enig defect en herbewerking (rework) door een keten van processtappen komt: hoe groot is de kans dat het voortbrengen van een product of dienst in één keer goed gaat, terwijl een aantal elkaar opvolgende stappen worden doorlopen binnen een proces. De RTY is een ratio die meet hoeveel eenheden 'door het proces rollen' zonder defects; hoe waarschijnlijk het is dat een eenheid wordt omgezet van input naar output, waarbij het voldoet aan de eisen van de klant.
Voordat aangegeven wordt hoe de RTY berekend kan worden, is het zinvol eerst in te gaan op de term Yield. 'Yield' kan vertaald worden met opbrengst, rendement. Traditioneel gezien is de opbrengst de verhouding tussen de goede items (die voldoen aan de specificaties) die je uit een proces haalt ten opzicht van het aantal grondstofitems dat je erin stopt.
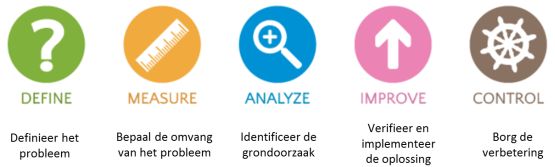
In het bovenstaande voorbeeld is de (traditionele) Yield van proces A te bereken als 347/352 x 100% = 98,6%. Binnen Lean Six Sigma wordt de traditionele Yield niet gebruikt als indicator voor de procesprestaties. Door de Yield te relateren aan het produceren zónder defecten, wordt de lat hoger gelegd! Alleen de eenheden die geproduceerd worden zonder defects worden gerekend tot de opbrengst van een proces.
Binnen proces A worden van de van de 352 (grondstof)items die het proces zijn ingegaan, bij een inspectie 103 items afgekeurd. Van de afgekeurde items kunnen 98 items alsnog worden hersteld (rework), maar vallen 5 items uit. Dit betekent dat er slechts (352 - 103 =) 249 items defect- en rework-vrij zijn geproduceerd. Binnen Lean Six Sigma wordt deze 'opbrengst' wel gebruikt als indicator voor de procesprestaties en de First Time Yield (FTY) genoemd.
De FTY staat voor de verhouding tussen het aantal items defect- en rework-vrij wordt geproduceerd ten opzichte van het aantal grondstofitems dat het proces is ingegaan. In het voorbeeld is de FTY dus gelijk aan 249/352 x 100% = 70,7%. De First Time Yield (FTY) verschilt van de traditionele yield "omdat ze in tegenstelling tot de traditonele opbrengst de harde werkelijkheid van de effectiviteit van het proces vastlegt, inclusief inspecties en het opnieuw bewerken". Anders gezegd: de traditionele opbrengst geeft een misleidend perspectief dat het effect van inspectie en herbewerking verbergt.
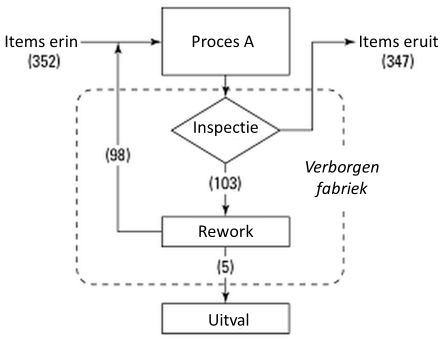
Binnen Lean Six Sigma worden alle handelingen die moeten worden verricht om een product te herstellen of over te doen, samengevat met de term 'verborgen fabriek'.

[De] verborgen fabriek is vaak een zeer dure fabriek, omdat er veel kosten moeten worden gemaakt waar geen opbrengsten tegenover staan. Het is puur verlies.
De verborgen fabriek is een natuurlijke uitwas van het onvermogen de vereiste specificatie op de juiste wijze na te leven in de eerste gang door het proces. Overal in de organisatie ontstaan verborgen fabrieken die zich nestelen als stilzwijgende aanhangsels van standaardprocessen. Het meten van de opbrengst met de first time yield-methode dwingt je objectief de effectiviteit van processen te beoordelen en accepteren.
Bij proces A beslaat de verborgen fabriek van inspectie en het opnieuw bewerken binnen het proces: 98,6% - 70,7% = 27,9% van de productie.
In de praktijk zal een proces vaak bestaan uit uit meer dan één achtereenvolgende processtappen. Om in dit geval de opbrengst van het proces te berekenen volgens de FTY-methode, moet je de FTY van alle stappen met elkaar te vermenigvuldigen. Deze metric wordt binnen Lean Six Sigma de Rolled Throughput Yield (RTY) genoemd. De RTY is de kans dat een eenheid alle processtappen de eerste keer met succes (defect- en rework-vrij) doorloopt.
Stel dat in het onderstaande voorbeeld een proces bestaat uit vijf processtappen (p1 t/m p5), met elk een FTY van 71%.
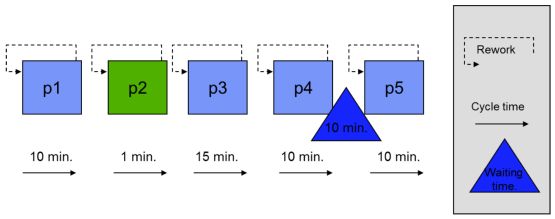
De formule voor de RTY is in dit geval:
RTY = FTYp1 x FTYp2 x FTYp3 x FTYp4 x FTYp5
RTY = 0,71 x 0,71 x 0,71 x 0,71 x 0,71 = 0,18 (18%)
Op basis van de gewenste RTY is af te leiden wat de benodigde prestaties moeten zijn van de afzonderlijke processtappen. Een gewenste RTY van 95%, bij een voortbrengingsproces dat bestaat uit vijf processtappen impliceert dat elke processtap 99% moet scoren (0,99 x 0,99 x 0,99 x 0,99 x 0,99 = 0,95).
Bron: Six Sigma voor Dummies, Craig Gygi, Neil DeCarlo en Bruce Williams en 111 instrumenten voor kwaliteitsverbetering - Ingedeeld volgens de Six Sigma-verbetercyclus, Arend Oosterhoorn
Laatst aangepast op vrijdag, 22 december 2017 20:54
LSS: Regels voor regelkaarten
Gepubliceerd in
Lean Six Sigma
Er zijn verschillende regelkaarten. De keuze welke regelkaart van toepassing is, hangt af van het type data, datgene wat je meet en de omvang en de gebruikte steekproeven (subgroepen).
(1) Bepaal van welke datatype de te meten procesinput of -output is

(2) Beoordeel steekproefgrootte (continue data => n?, discrete data: constant vs. variabel)
(3) Bepaal bij discrete data of sprake is van: (a) beoordelen van één bepaald kenmerk per eenheid, óf (b) het tellen van kenmerken per eenheid.

Bij de defecte eenheden kan elk item dat deel uitmaakt van de steekproef worden geclassificeerd in één van de twee categorieën (goed/fout, defectief/niet-defectief). Bij elke steekproef kun je een verhouding (percentage) berekenen door het aantal items te kennen dat voldoet aan het beoordeelde kenmerk. Als het gaat om defecten per eenheid, kan elk item meer dan één defecten of ongewenste eigenschappen hebben. Je kunt per eenheid het aantal defecten tellen, waarbij het totale aantal groter kan zijn dan de omvang van de steekproef (n).
Laatst aangepast op zondag, 31 december 2017 07:49
LSS: A3 als probleemoplossingsmethode
Gepubliceerd in
Lean Six Sigma

A3 is
De A3-methode is een gestructureerde werkwijze voor het oplossen van problemen. Op een vel papier met A3 formaat, dwingt een strak sjabloon je om het probleem en de weg naar de oplossing helder en beknopt te formuleren. Feitelijk wordt je stap voor stap door een PDCA-cyclus geloodst. De titel van de A3 is een pakkende titel die aangeeft welke probleem gaat worden aangepakt. Nadat je het probleem duidelijk hebt, wordt je gedwongen eerst op zoek te gaan naar de diepere achterliggende oorzaken (root causes), voordat je in allerlei oplossingen schiet.
Plan
(1) Beschrijf de huidige situatie: wat is de achtergrond van het probleem? Wat doet er 'pijn'? Wat zijn de symptomen?
(2) Beschrijf het probleem: wat is de afwijking tussen de gewenste situatie en de huidige situatie (visueel, concreet)
(3) Formuleer de doelstelling: wanneer is het probleem opgelost? Wat is het beoogde resultaat of effect?
(4) Analyseer de grondoorzaken (5 x waarom)
(5) Definieer tegenmaatregelen: wat ga je doen om het probleem tegen te gaan en welke impact verwacht je hiervan? Hoe toets je of de tegenmaatregelen effectief zijn?
Do
(6) Experimenteer of de ingevoerde tegenmaatregel voor de bronoorzaak het verwachte resultaat weergeeft
Check
(7) Controleer of tegenmaatregelen effectief zijn: de mate waarin implementatie geslaagd is, bepaalt de aanbevolen/noodzakelijke vervolgacties (follow-up)
(8) Visueel maken
(9) Formuleer vervolgacties: als de doelstelling is gehaald kun je A3 afsluiten, als dit niet zo is, herzie dan de A3.
Act
Uitrollen van de tegenmaatregelen en definitief maken (incl. aantonen dat tegenmaatregelen blijvend functioneren).
Geneviève van Gemert maakte een handige instructie voor het maken van een A3.
Wil je zelf aan de slag, zie dan mijn mijn slidesharepresentatie Bluff Your Way Into A3-methode (voor probleemoplossing)

Zie ook:
Laatst aangepast op donderdag, 21 december 2017 20:39
Statistische concepten en hulpmiddelen: frequentieverdeling
Gepubliceerd in
Lean Six Sigma
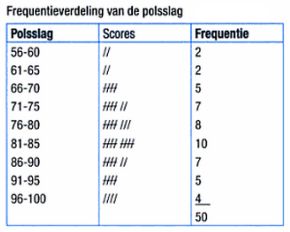
Een frequentie is het aantal malen dat een waarde van een variabele voorkomt. Door de aantallen te ordenen in een tabel of in een grafiek ontstaat een zogenaamde frequentieverdeling. Een grafiek waarmee een frequentieverdeling wordt weergegeven heet een histogram.
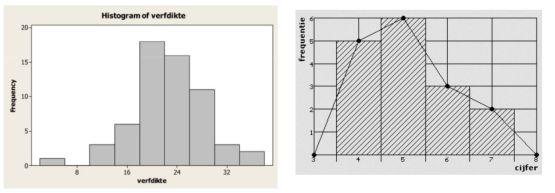
De oppervlakte van de kolommen in een histogram is gelijk aan de relatieve frequentie van de gegroepeerde waarden. In tegenstelling tot het klassieke staafdiagram sluiten in een histogram alle kolommen tegen elkaar. De middelpunten van de staven van een histogram worden soms met elkaar verbonden. De curve die door deze lijn wordt gevormd, wordt een frequentiepolygoon genoemd.
Bij het doen van onderzoek moet je als onderzoeker vaak zelfs de klassen bepalen. Door het gebruik van klassen treedt verlies van informatie op, maar daar staat tegenover dat er meer inzicht in de waarnemingen ontstaat. Als vuistregel voor het aantal klassen kies je door de wortel te nemen van het totaal aantal waarnemingen. De klassen hoeven niet allemaal even groot te zijn. Hoe groter de klassen, hoe meer informatie verloren gaat. Vaak worden voor gebieden waar weinig waarnemingen zijn, de klassen wat breder gemaakt.
De klassenbreedte is gelijk aan het verschil tussen de bovengrens van een klasse en de ondergrens van een klasse. Het aantal waarnemingen dat in een klasse valt, is de absolute frequentie. Wanneer je frequentieverdelingen met een verschillend aantal waarnemingen wilt kunnen vergelijk, kun je gebruik maken van de relatieve frequentie.

De laagste en hoogste waarde van de klasse noemen we de klassengrenzen. Klassen mogen elkaar niet overlappen. Het gemiddelde van de getallen die in een klasse kunnen voorkomen vormt het klassenmidden. Dit wordt ook wel gedefinieerd als de som van de onder- en bovengrenzen van een klasse, gedeeld door twee.
Wanneer er sprake is van ongelijke klassenbreedten, kun je de frequenties van waarnemingen niet direct vergelijken. Daarvoor zul je eerst de frequentie per gelijke eenheid moeten berekenen. Dit doe je door de frequentiedichtheid te berekenen, die onafhankelijk is van de gekozen klassenbreedte.

Door de frequentie van waarnemingen van verschillende klassen bij elkaar op te tellen, krijg je de cumulatieve frequentie.
Binnen Lean Six Sigma kun je een histogram gebruiken voor het visueel presenteren van data. Het doel van een histogram is het op een eenvoudige weergeven van de spreiding van gegevens. Door in het histogram ook de klantspecificaties op te nemen, zie je hoe het proces gecentreerd is rond de klantspecificaties en of de spreiding binnen de specificatielimieten valt. Het histogram geeft inzicht in de variatie in de data van een dataset en de ligging en geeft daarmee direct een indruk of het proces in staat is te voldoen aan de gestelde klanteisen ('procesprestaties').
Het histogram kan ook gebruikt worden om optisch te beoordelen of er sprake is van een normale verdeling. Bij een normale verdeling heeft het frequentiepolygoon een symmetrische klokvorm. Omdat de optische beoordeling subjectief is, is het vaak aan te bevelen om de gegevens weer te geven door middel van een normaliteitsplot (probability plot).
Om een histogram te maken, tel je de frequenties waarin de verschillende klassen (categorieën) voorkomen. Op de horizontale as geef je de relevante verdeling weer van de klassen. Elke klasse wordt vertegenwoordigd door een staaf ('balk'). Op de verticale as geef je de frequentie weer in absolute waarde of relatieve percentages. De hoogte van de weergegeven staven komt overeen met de frequentie van de betreffende klasse. Het is aan te bevelen een histogram alleen te gebruiken bij grotere datasets (tenminste 50-100 datapunten). Te kleine datasets leiden tot misleidende interpretaties. Als je meerdere pieken in het histogram ziet, kan de dataset te klein zijn of van meerdere metingen afkomstig. Als dat het geval is (her)overweg datastratificatie. Een 'gestratificeerd' histogram helpt om proceskenmerken te identificeren die mogelijk inzicht geven in mogelijke oorzaken van het probleem.

De frequentie (f) van een bepaalde gebeurtenis is het aantal keren dat de gebeurtenis is voorgekomen. De term gebeurtenis moet men hier zeer ruim nemen: het kan het verkrijgen van 'kruis' zijn bij het gooien van een munt, maar ook het vinden van iemand die in de klasse 'blond haar' valt, een proefwerkcijfer van een 7 gehaald heeft of een lengte tussen 170 en 179 heeft.
(...)
Een frequentieverdeling is een weergave van een aantal categorieën of klassen met de bijbehorende frequenties. Een frequentieverdeling is dus gebaseerd op de uitkomsten van een onderzoek. Het totaal aantal onderzochte personen (vaak aangeduid met de letter (n) dient onderaan de tabel te worden vermeld. Een frequentieverdeling kan weergegeven worden in een tabel, of in een figuur of grafiek. ... Veel gebruikte grafische vormen zijn het kolommendiagram, taartpuntdiagram en staafdiagram die alle gebruikt worden voor kwalitatieve gegevens als haarkleur, beroep, en dergelijke; voor het weergeven van numerieke gegevens gebruikt men het histogram, het stamdiagram en de frequentiepolygoon.
Frequentieverdelingen
Wanneer we een groot aantal gegevens hebben verzameld ten behoeve van een bepaald onderzoek dan is het doorgaans noodzakelijk dat deze gegevens nader bewerkt worden. Het op overzichtelijke wijze presenteren van deze gegevens is hierbij belangrijk. Om personen die niet betrokken zijn geweest bij het onderzoek een idee te geven van de resultaten, is het vaak nuttig om de gegevens te verwerken in een tabel of een grafiek.
Op deze manier kan een zeker overzicht van de betrokken variabelen verkregen worden, waardoor het patroon van de gegevens tot uiting komt. Voordat van een hoeveelheid 'losse' gegevens een tabel of een grafiek vervaardigd kan worden, is het noodzakelijk deze te ordenen.
Hierbij wordt de verzameling van mogelijke uitkomsten verdeeld in een aantal intervallen of groepen, die we klassen zullen noemen. Het in een klasse verdelen van het totale bereik van de variabele noemt men het maken van een klasse-indeling.
(...)
Bij het maken van een correcte klasse-indeling moet erop gelet worden dat rekening gehouden wordt met alle mogelijke uitkomsten van de betrokken variabele. Voor elke uitkomst moet een plaats zijn. Anderzijds moet ervoor gewaat worden dat er geen overlappingen plaatsvinden waardoor een bepaalde uitkomst in meer dan één klasse thuishoort. Een klasse-indeling die alle mogelijkheden overdekt maar geen overlappingen kent, noemen we een categorisch systeem.
Zodra er een dergelijke indeling in klassen gemaakt is, kan er 'geturfd' worden. Op deze manier kan worden vastgesteld hoe vaak er een waarneming behorend tot een bepaalde klasse verricht is. Het aantal waarnemingen in een bepaalde klasse noemt men de frequentie. De verdeling die aldus voor de klassen ontstaat, noemt men een frequentieverdeling.
(...)
Relatieve frequeties
... Nadat er een indeling in klassen tot stand is gekomen, kunnen de waargenomen uitkomsten geteld worden. Hierdoor ontstaan absolute frequenties. De som van de frequenties is uiteraard gelijk aan het totaal aantal waarnemingen.
Wanneer we de frequentie per klasse delen door het totale aantal waarnemingen, ontstaan relatieve frequenties. Relatieve frequenties kunnen van belang zijn bij het vergelijken van verschillende frequentieverdelingen.
Frequentieverdeling
De frequentie is het aantal keren dat een verschijnsel voorkomt. Bijvoorbeeld: er deden 20 mannen en 40 vrouwen mee aan het onderzoek. Als je alle frequenties in een tabel zet, heb je een frequentieverdeling. Het doel van de frequentieverdeling is om de resultaten van het onderzoek overzichtelijk weer te geven. We onderscheiden vier soorten frequentieverdelingen:
- ongegroepeerde frequentieverdeling
- gegroepeerde frequentieverdeling
- relatieve frequentieverdeling
- cumulatieve frequentieverdeling
Ongegroepeerde frequentieverdeling
Een ongegroepeerde frequentieverdeling wordt gebruikt wanneer van een variabele slechts weinig waarden voorkomen, zoals bij de vraag ‘Wat is uwleeft ijd?’ in een klas propedeuse-studenten van een hbo-instelling. Als van een variabele veel verschillende waarden voorkomen, is een ongegroepeerde frequentieverdeling niet overzichtelijk; zodra een variabele meer verschillende waarden kan aannemen, neemt de overzichtelijkheid van de tabel af.
(...)
Gegroepeerde frequentieverdeling
Als een variabele veel voorkomende waarden heeft en de waarde in groepen kan worden ingedeeld, ligt het voor de hand om te kiezen voor een gegroepeerde
frequentieverdeling.
Bij een gegroepeerde frequentieverdeling zet je de frequentie van een groep in een tabel. De frequentie van een groep of klasse is het totaal van de frequenties
van de afzonderlijke waarden die tot een bepaalde klasse behoren.
Als je bijvoorbeeld aan 150 verschillende mensen in een supermarkt hebt gevraagd ‘Wat is uw leeftijd?’, is de kans groot dat je veel verschillende
waarden hebt. In deze situatie ligt het voor de hand om de waarden in
klassen in te delen, zoals in tabel 8.3.
(...)
Relatieve frequentieverdeling
Als je groepen wilt vergelijken, kun je de relatieve frequentieverdeling nemen. Bij een relatieve frequentieverdeling laat je de frequenties van de verschillende klassen als een percentage zien.
(...)
Cumulatieve frequentieverdeling
De cumulatieve frequentieverdeling geeft het totale aantal frequenties weer dat zich onder een bepaalde klassengrens bevindt. Je telt als ware de frequenties tot dan toe bij elkaar op. Je doet dit om te weten welk deel van een verdeling onder een bepaalde waarde ligt. De meting moet wel op minstens ordinaal niveau zijn. Je zet de vragen in de rijen en de antwoordmogelijkheden in de kolommen van een tabel.
(...)
Ook is het mogelijk om een kruistabel te maken, waarin meerdere variabelen tegenover elkaar staan. Door de resultaten in een kruistabel te zetten, wordt het verband tussen de variabelen zichtbaar.
De onafhankelijke variabele zet je in de kolommen, de afhankelijke in de rijen. Verticaal percenteer je tot 100%, zodat je gemakkelijk kunt vergelijken. Daarna kun je met een chi-kwadraattoets onderzoeken of het verband tussen de variabelen significant is.
Zie ook: LSS: Probability Plot (normaliteitsplot)
Bron:
Laatst aangepast op zondag, 15 april 2018 11:33
LSS: Taguchi verliesfunctie
Gepubliceerd in
Lean Six Sigma
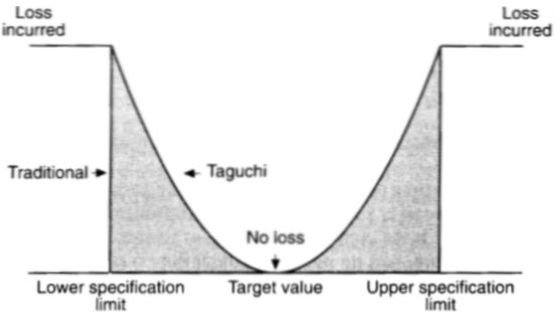
De bovenstaande kromme wordt Taguchi's verliesfunctie genoemd, vernoemd naar Genichi Taguchi. De figuur laat zien dat de traditionele alles-of-niets-kijk op kwaliteit (= voldoen aan specificaties). Alleen als specificaties niet worden nageleefd, worden onnodige kosten gemaakt. Binnen (Lean) Six Sigma is de visie op kwaliteit anders: het doel is dat een kenmerk volgens target functioneert, met zo min mogelijk variatie. Dit betekent dat er al extra kosten worden gemaakt zodra de performance zich van de target verwijderd.
Bron: Six Sigma voor Dummies, Craig Gygi, Neil DeCarlo en Bruce Williams
Laatst aangepast op zondag, 31 december 2017 07:49
LSS: DMAIC (2)
Gepubliceerd in
Lean Six Sigma
Laatst aangepast op zondag, 31 december 2017 07:53
LSS: Effort/Benefit-Matrix
Gepubliceerd in
Lean Six Sigma
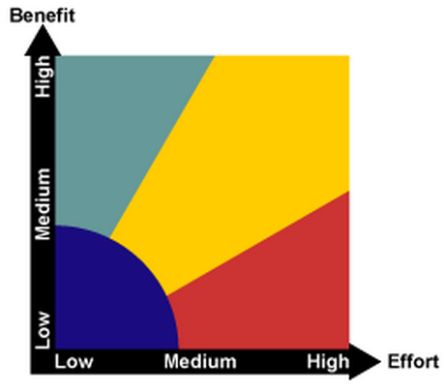
Een Effort/Benefit-Matrix is een grafisch hulpmiddel voor het evalueren van mogelijke oplossingen in termen van de benodigde inspanning en de verwachte baten. De matrix helpt bij het prioriteren van oplossingen, waarbij de voorkeur zal uitgaan naar oplossingen die met weinig inspanning grote voordelen opleveren.
Voor oplossingen in het rode gebied (effort = hoog, benefit = laag) geldt dat implementatie geen zin heeft. Bij oplossingen in het gele gebied (effort = hoog, benefit = hoog) is nader onderzoek nodig om te bepalen of implementatie al dan niet zinvol is. In het groene gebied (effort = laag, benefit = hoog) heeft het zin een DMAIC-project te starten. Het blauwe gebied (effort = laag, benefit = laag) bevat oplossingen met een laag potentieel, maar gezien het quick win-gehalte, zeker het overwegen waard.
Bron: Lean Six Sigma Toolset, Stephan Lunau
Laatst aangepast op donderdag, 21 december 2017 20:42
LSS: Probability Plot (normaliteitsplot)
Gepubliceerd in
Lean Six Sigma
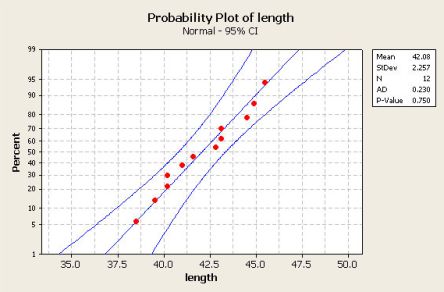
Veel statistische technieken zijn gebaseerd op de veronderstelling dat de populatie bij benadering normaal verdeeld is. Daarom is het belangrijk eerst te bepalen of de steekproefgegevens uit een normaal verdeelde populatie komen, voordat je deze technieken kan toepassen.
Een beoordeling aan de hand van een frequentieverdeling (histogram, dot plot) biedt niet altijd voldoende zekerheid. De Probability Plot (normaliteitsplot) heeft een zodanige schaalverdeling dat de grafiek van een theoretisch zuivere normale verdeling een rechte lijn wordt. Hoe beter data in een normaliteitsplot op een rechte lijn liggen des te beter de data een normale verdeling benaderen. Ter vergelijking kun je de ideale lijn laten tekenen.
Bij een Probability Plot worden de waarnemingen in een gegevensverzameling van klein naar groot geordend en vervolgens in een grafiek uitgezet tegen de bijbehorende verwachte z-waarden als de waarnemingen uit een normale verdeling komen. Eigenlijk is een Probability Plot een spreidingsdiagram met de gesorteerde gegevenswaarden op de ene as, en de bijbehorende verwachte z-waarden van een standaardnormale verdeling op de andere as. Het berekenen van de verwachte standaardnormale z-scores is niet iets wat je handmatig doet, maar over kunt laten aan een statistisch programma, zoals Minitab.
Als de gegevens inderdaad uit een normale verdeling komen, zullen de gevonden punten op een rechte lijn liggen. Als de z-waarden niet bij benadering op een rechte lijn liggen, is dat een duidelijke aanwijzing dat er geen sprake is van een normale verdeling. In het bovenstaande voorbeeld zijn op basis van een betrouwbaarheidsinterval van 95%, twee 'limietlijnen' getekend, waarbinnen het merendeel van de punten moet liggen om van een rechte lijn te kunnen spreken.
Laatst aangepast op zondag, 31 december 2017 07:52
LSS: Dotplot
Gepubliceerd in
Lean Six Sigma
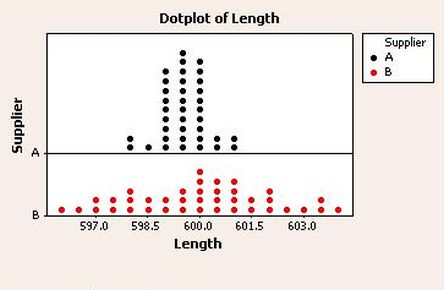
Een Dotplot (puntendiagram) is een alternatief voor een histogram. In een puntendiagram kun je op eenvoudige manier weergeven wat de spreiding is van continue data. Het helpt bij het zichtbaar maken van uitschieters bij kleine hoeveelheden data.
Langs de horizontale as staan de mogelijke waarden en op de verticale as wordt elke meting vertegenwoordigd door 1 punt. Bij grote hoeveelheden datapunten kan elke punt ook meer dan één resultaat weergeven.
Laatst aangepast op zondag, 31 december 2017 07:52
Statististische concepten & hulpmiddelen: Pareto-diagram
Gepubliceerd in
Lean Six Sigma
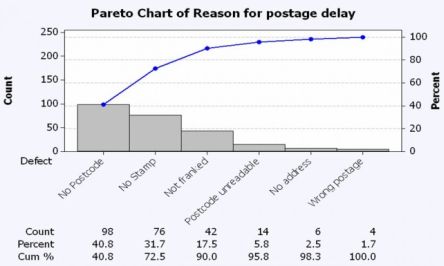
Een Pareto-diagram is een staafdiagram waarin de staven van hoog naar laag zijn geordend. Het diagram laat zien wat de 'kritieke bijdragers' zijn.
Een grafisch hulpmiddel dat vaak gebruikt wordt voor het identificeren van verbetergebieden.
Kenmerken van een pareto chart:
- Helpt bij het prioriteren van problemen (80/20-regel)
- Data moeten nominale schaal (tellen) of van een ordinale schaal ('summarized') zijn
- Identificeert 'the vital few from the trivial many'.
Het Paretodiagram is een staafdiagram. Op de horizontale as staat een bepaald verschijnsel weergegeven, op de verticale as de frequentie of omvang van dat verschijnsel. Op de horizontale as staat het verschijnsel met de hoogste frequentie of de grootste omvang het dichtst bij de verticale as
Pareto-analyse
Vilfredo Pareto (1843-1923), een Italiaans econoom, ontdekte dat ongeveer 80% van een land in handen is van ongeveer 20% van de mensen. ... [Dit illustreert] het idee van het 'weinige belangrijke en het vele onbelangrijke', het Pareto-principe. ... In het algemeen omvat Pareto-analyse het indelen van objecten in categorieën en het bepalen welke categorieën de meeste waarnemingen bevatten. Dit zijn de 'weinige belangrijke' categorieën. Pareto-analyse wordt tegenwoordig in de industrie gebruikt als een hulpmiddel voor het vaststellen van problemen. Managers en medewerkers gebruiken Pareto-analyse om vast te stellen wat de belangrijkste problemen of oorzaken van problemen zijn die voorkomen. Kennis van de 'weinige belangrijke' problemen stelt het management in staat om prioriteiten te stellen en zijn inspanningen voor het oplossen van problemen doelgericht te gebruiken.
Het belangrijkste hulpmiddel van Pareto-analyse is het Pareto-diagram. Het Pareto-diagram is niets anders dan een staafdiagram van de frequenties of relatieve frequentie, met de balken gesorteerd op afnemende hoogte van links naar rechts langs de horizontale as.
Bron:
Laatst aangepast op vrijdag, 18 januari 2019 07:29
|