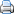LSS: Check sheet (turflijst)
Gepubliceerd in
Lean Six Sigma

Een check sheet (turflijst) is een hulpmiddel voor het op overzichtelijke wijze verzamelen van data. Door een gestructureerde lijst te maken van onderwerpen die gemeten moeten worden, wordt het verzamelen van data over een proces(stap) overzichtelijk én visueel gemaakt en daardoor eenvoudiger en minder gevoelig voor fouten.
Een check sheet wordt beschouwd als één van de zeven grafische basistechnieken binnen kwaliteitsmanagement.
Bron: 111 instrumenten voor kwaliteitsverbetering - Ingedeeld volgens de Six Sigma-verbetercyclus, Arend Oosterhoorn en http://en.wikipedia.org/wiki/Seven_Basic_Tools_of_Quality
Laatst aangepast op vrijdag, 22 december 2017 20:55
LSS: Binomiale verdeling
Gepubliceerd in
Lean Six Sigma

In 1713 verscheen het eerste leerboek over kansrekening: 'Ars conjectandi' van Jacob Bernoulli, wat betekent 'de kunst van het gissen'. Hierin staat een studie van dit soort kansexperimenten. Een experiment waarbij je maar twee uitkomsten hebt, wordt dan ook wel een Bernoulli-experiment genoemd. De ene uitkomst heet wel 'succes', de andere 'mislukking'. Als je een Bernoulli-experiment een aantal keer (onafhankelijk van elkaar) herhaalt, heb je een zogenaamd binomiaal kansexperiment. 'Binomiaal' betekent letterlijk 'twee-termig'.
Een binomiaal kansexperiment is dus een kansexperiment dat vertaald kan worden naar een vaas met balletjes in twee kleuren. Daaruit pak je aselect met terugleggen een aantal balletjes. Je telt het aantal balletjes die je gepakt hebt van een van de kleuren.
In de kansrekening en de statistiek is de binomiale verdeling een verdeling van het aantal successen X in een reeks van n onafhankelijke alternatieven alle met succeskans p. Zo'n experiment wordt ook wel een Bernoulli-experiment genoemd.
In het geval n = 1, komt de binomiale verdeling overeen met de Bernoulli-verdeling.
Zie ook: Statistische concepten en hulpmiddelen: binomiale verdeling
Bron: http://www.wageningse-methode.nl/download/Kansrekening2.pdf
Laatst aangepast op maandag, 23 april 2018 20:00
LSS: Statistisch toets-selectie
Gepubliceerd in
Lean Six Sigma
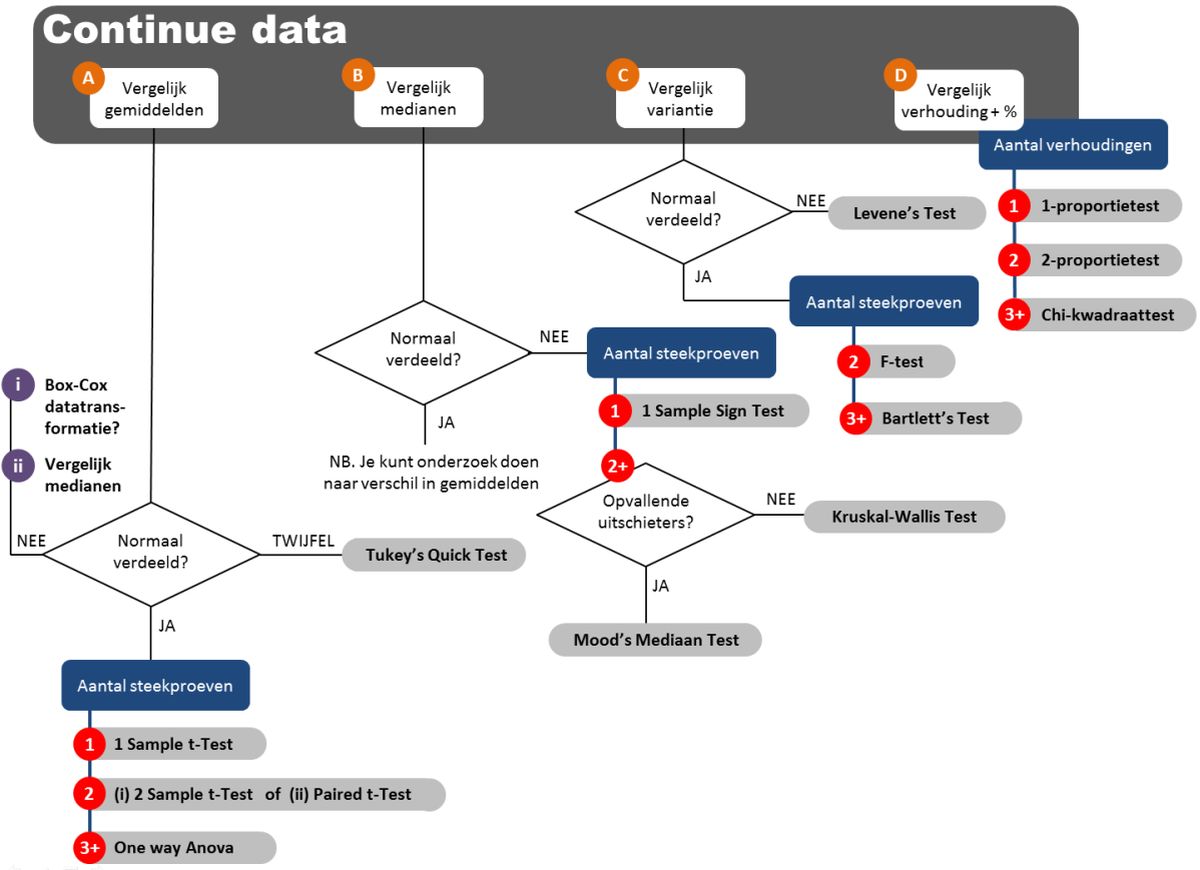
Het bovenstaande stroomschema geeft aan in welke situatie je voor continue variabelen welke statistische toets kunt gebruiken. Hieronder zie je wanneer je welke statistische toets toepast bij discrete data:
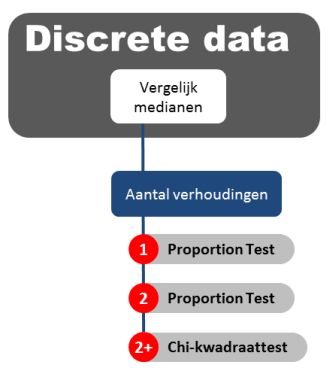
Een andere beslistabel waarmee je kunt bepalen welke statistische toets wanneer toe te passen, is de onderstaande:
Laatst aangepast op vrijdag, 22 december 2017 21:00
LSS: Control Chart-selectie
Gepubliceerd in
Lean Six Sigma
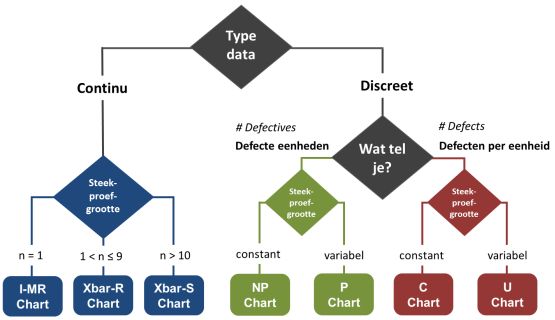
Binnen Statistical Process Control (SPC) is de keuze voor de juiste control chart afhankelijk van het soort data en de omvang van de steekproeven.
In totaal kun je kiezen uit zeven control charts:
-
I-MR Chart.
-
Xbar-R Chart.
-
Xbar-S Chart.
-
NP Chart.
-
P Chart.
-
C Chart.
-
U Chart.
De eerste drie control charts gebruik je voor continue data. De overige vier zijn bruikbaar bij discrete data:

Bij discrete data hangt de keuze af van: (a) of er sprake is van defecten per eenheid of defecte eenheden, en (b) of de omvang van de steekproef constant of variabel is. Bij het selecteren, gebruiken van de control chart voor discrete gegevens is de steekproefgrootte normaliter groter dan 50 (n > 50) en moet er sprake zijn van minimaal 5 defecten.
Laatst aangepast op zondag, 31 december 2017 07:50
LSS: Regressie-analyse
Gepubliceerd in
Lean Six Sigma
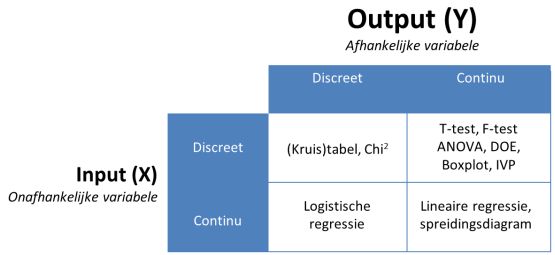
Regressie-analyse is een statistische techniek voor het onderzoeken van het causale verband tussen variabelen. Het onderzoek is erop gericht te analyseren in welke mate een verandering in één of meer variabelen leidt tot een verandering in een andere variabele. Het doel is het verklaren of voorspellen van een bepaalde variabele op basis van één of meerdere andere variabelen. Er wordt een lineaire relatie verondersteld tussen de afhankelijke (te voorspellen of te verklaren) variabele Y en een (of meerdere) onafhankelijke variabele X. Deze lineaire relatie kan worden uitgedrukt in termen van een regressievergelijking.
Regressie-analyse is nauw verwant met correlatieonderzoek. Beide technieken onderzoeken het verband tussen twee variabelen. Bij regressie ga je een stap verder dan bij correlatie. Je probeert aan de hand van de ene (onafhankelijke) variabele de veranderingen in de andere (afhankelijke) variabele statistisch te voorspellen, waarbij een regressievergelijking wordt opgesteld. Bij een correlatieanalyse is er geen duidelijke onafhankelijke variabele. Je wilt onderzoeken óf er een mogelijk verband bestaat tussen twee variabelen en hoe sterk dit verband is. De variabelen zijn 'gelijkwaardig'. Hét verschil tussen correlatie en regressie is statisch relevant, maar wordt in de praktijk niet zo strikt gehanteerd. Wanneer het doel van een onderzoek is een variabele te voorspellen uit de andere, spreekt men gewoonlijk over regressie. Is het doel slechts een index te geven van de mate van samenhang tussen twee variabelen, dan spreekt men van correlatie.
Associatie en correlatie zijn twee termen voor samenhang of afhankelijkheid tussen variabelen. Twee variabelen zijn afhankelijk, als de kans op een uitkomst op de ene variabele afhankelijk is van de uitkomst op de andere variabele. We spreken meestal van associatie, als de samenhangende variabelen discreet zijn, en van correlatie, als de variabelen continu zijn. Erg consequent wordt aan deze terminologie echter niet vastgehouden. Voor het bepalen van een samenhang is het belangrijk om vast te stellen op welk niveau de variabele gemeten is. Alleen wanneer beide variabelen op hetzelfde niveau zijn gemeten is er een samenhang te berekenen. Regressie-analyse maakt gebruik van het rekenkundig gemiddelde. Daarom moeten beide variabelen minstens interval meetniveau hebben. Ook mogen de variabelen geen extreme waarden hebben, aangezien zij de richting van de regressielijn sterk kunnen beïnvloeden in een kleinedata-set (van enkele tientallen waarnemingen).
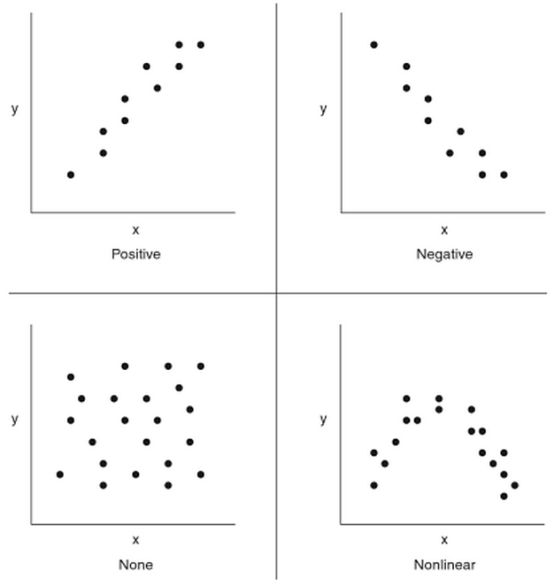
Formeel spreek je spreek van associatie bij variabelen op nominaal/ordinaal meetniveau en over correlatie bij variabelen op een interval/ratio meetniveau. Je spreekt dus strikt genomen alleen van correlatie als twee continue variabelen samenhangen of afhankelijk zijn. De uitkomsten kan je weergeven in een spreidingsdiagram. De sterkte van een (lineaire) correlatie meten we met een correlatiecoëfficiënt (r), waarbij de waarde altijd ligt tussen -1 en +1. Correlatie tussen twee variabelen wil nog niet zeggen, dat de verschijnselen, die door die variabelen worden gemeten, een causaal verband hebben. Soms berust het geheel op toeval en men spreekt dan wel van een schijncorrelatie (pseudo-correlatie).
De aard van de relatie tussen continue variabelen kan worden samengevat in één getal, de correlatiecoëfficiënt (r). De officiële naam is Pearson product-moment correlaticoëfficiënt (pmcc) en de kortste weergave hiervoor is rxy (r van relatie, x en y als verkorte aanduiding van de beide variabelen). Bij het karakteriseren van het verband tussen variabelen zijn er drie aspecten waar je op kunt letten:
-
Aanwezigheid: is er een systematisch, statistisch significant verband, tussen twee variabelen (zie: sterkte).
-
Richting: het teken voor de coëfficiënt geeft de richting van het verband aan. Een positief verband tussen variabelen betekent dat hoge waarden op de ene variabele samengaan met hoge waarden van de andere; hetzelfde geld voor lage waarden. Een negatieve correlatie betekent dat hoge waarden op de ene variabele samengaan met lage waarden op de andere variabele. Hoe groter de absolute waarde van de correlatiecoëfficiënt, des te sterker het verband tussen beide variabelen
-
Sterke van het verband: afhankelijk van het soort verband dat wordt onderzocht kan de sterkte van de samenhang tussen twee variabelen worden voorgesteld als sterk, gematigd, zwak of niet-bestaand. De correlatiecoëfficiënt geeft aan in hoeverre de relatie tussen beide variabelen lijkt op een rechte lijn. De sterkte van het verband tussen twee variabelen wordt uitgedrukt in een getal tussen -1 en +1. Een waarde van -1 of +1 duidt erop dat de punten precies op een rechte lijn liggen; er is sprake van een perfect (lineair) verband. Als de correlatiecoëfficiënt 0 is, is er geen sprake van een rechtlijnig verband. Tussenliggende waarden duiden op enig verband tussen de variabelen.
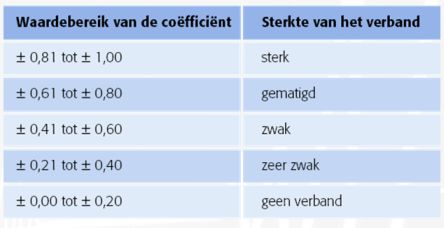
De grootte van de correlatie kan zowel in woorden als getallen beschreven. Correlaties van 0,90 of hoger noemen we meestal 'groot', 'sterk' of 'hoog'. Correlaties van 0,30 of minder noemen we meestal klein, zwak of laag. Correlaties tussen 0,30 en 0,80 noemen we meestal gematigd of bescheiden. Een andere indeling is:
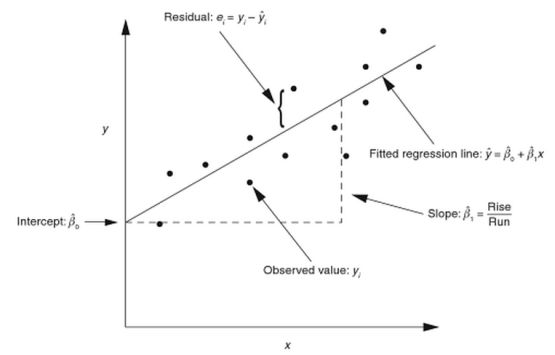
Enkelvoudige lineaire regressie is de meest simpele vorm van regressie heeft als doel het analyseren van een continue, onafhankelijke variabel en een continue, afhankelijke variabele. Bij het onderzoeken van de correlatie tussen twee continue variabelen, wordt geanalyseerd of een continue variabele (Y) door een andere continue variabele (X) wordt verklaard of voorspeld: Y=F(X). De regressievergelijking is de vergelijking die de samenhang weergeeft tussen de afhankelijke variabele en een of meer andere variabelen die haar beïnvloeden (de onafhankelijke variabelen). Met de regressievergelijking is het mogelijk de procesprestatie (Y) te voorspellen bij een specifieke waarde van de variabele X. De vergelijking kan worden gevisualiseerd door middel van een zogenaamde regressielijn die staat voorde lijn waarmee de ligging van een puntenwolk (verzameling van punten die ontstaat als je de meetwaarden van twee variabelen in een assenstelsel tegen elkaar uitzet) kan worden aangeduid.
De regressievergelijking staat voor de lineaire functie die in staat is zoveel mogelijk datapunten te verklaren, en de datadeviatie (residuals) van de functie te minimaliseren. Het enkelvoudige lineaire regressiemodel heeft als formule: Y = a + bx + E (epsilon). Binnen deze formule staat Y voor de afhankelijke variabele, en X voor de onafhankelijke variabele (regressor). De 'a' en 'b' staan voor de regressiecoëfficiënten, waarbij 'a' aangeeft waar de regressielijn de y-as snijdt (ook wel 'axis intercept' of constante genoemd; dit is het snijpunt met de y-as als X=0) en 'b' staat voor de hoek van de regressielijn (hellingsgetal, richtingcoëfficiënt). In de vergelijking staat de E (epsilon) voor de foutvoorwaarde (het residu, ook wel error term; residuals genoemd); 'fout' in de zin dat het gaat om de afwijking tussen de geobserveerde waarde van y en de voorspelde waarde van y. De analyse van residuen op de grafieken biedt belangrijk inzicht over hoe goed het model past. Als de residuen normaal zijn verdeeld, dan liggen ze grofweg op een lijn in een normaliteitsplot plot en de histogram heeft de vorm van een normale verdeling.
Er is sprake van een negatief verband als er een verband bestaat tussen twee variabelen waarbij hoge (lage) waarden van de ene variabele vaak tegelijk optreden met lage (hoge) waarden van de andere. Een positief verband staat voor een verband tussen twee variabelen waarbij hoge (lage) waarden van de ene variabele vaak tegelijk optreden met hoge (lage) waarden van de andere. Bij een 'perfecte' positieve correlatie is de correlatiecoëfficiënt r gelijk aan 1. Bij een 'perfecte' negatieve correlatie is r = -1. Als er geen correlatie is dan r = 0. Dus hoe meer r afwijkt van nul hoe groter de correlatie.
In het bovenstaande voorbeeld is met Minitab een regressie-analyse uitgevoerd, waarbij de correlatie is onderzocht tussen Y en X. Het resultaat kan als volgt
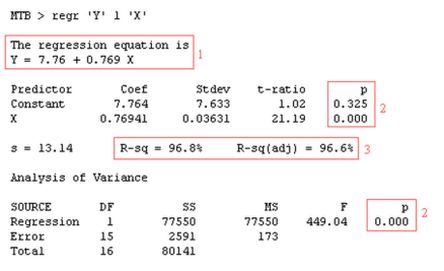
De regressielijn wordt geschat met behulp van de kleinste kwadratenmethode (Gauss): neem die lijn waarvoor de som van de gekwadrateerde residuen zo klein mogelijk is.
Regressievergelijking
Bij (1) zie je de regressievergelijking Y= a + bX, waarbij 'a' = 7,76 en 'b'= 0,769.
Toetsen lineair verband
Het doel van de regressie-analyse is te onderzoeken of de variabele X de variabele Y beïnvloedt. Bij lineaire regressie doe je dit door statistisch te toetsen of de regressie significant is. Concreet houdt dit in dat je toetst of parameter 'b' (de hellingscoëfficiënt) een waarde heeft die significant van 0 verschilt. De nulhypothese is dan ook gelijk aan 'b' = 0 (er is geen lineair verband). De alternatieve hypothese is dat 'b' ongelijk is aan nul (en er dus wél sprake is van een lineair verband). Tot zover de theoretische achtergrond. Als je kijkt naar de gevonden p-waarde (2), is deze lager dan 0,05 en is er (omdat we de nulhypothese verwerpen) reden aan te nemen dat sprake is van een lineair verband.
Determinatiecoëfficiënt
De correlatiecoëfficiënt R is een maat voor de sterkte van het lineaire verband tussen de onafhankelijke variabele Y en de instelvariabele X. De waarde van R ligt altijd tussen -1 en +1 waarbij waarden in de buurt van —1 en +1 een grote lineaire correlatie. Een waarde voor R rond 0 geeft aan dat er geen lineair verband aanwezig is tussen Y en X. In dit voorbeeld is er sprake van en sterk positief lineair verband tussen X en Y. De 'R-Sq' staat voor R-square, de determinatiecoëfficiënt, die te berekenen is door het kwadrateren van de correlatiecoëfficiënt. R-Sq ligt altijd tussen 0 en 1, omdat R altijd tussen -1 en +1 ligt. De determinatiecoëfficiënt staat voor het aandeel (percentage) van de totale variantie in de ene variabele dat statistisch verklaard wordt door de andere: de verklaarde variantie gedeeld door de totale variantie. Anders gezegd: de determinatiecoëfficiënt (R-sq) geeft aan welk gedeelte van de totale variantie in de afhankelijke variabele Y verklaard wordt door het regressiemodel. 'R-sq (adj)' is de Adjusted R-square: een reëlere schatting van de determinatiecoëfficiënt. Voor de meetgegevens van X en Y wordt dus 99,8 % van de veriantie in Y verklaard door het verkregen lineaire regressiemodel. Goed nieuws: dit wijst erop dat je de belangrijkste invloedsfactor van het proces te gevonden hebt.
In plaats van ons te concentreren op één enkele variabele (univariate regressie-analyse) is het vaak interessant om de relatie te bestuderen tussen een afhankelijke variabelen en meer dan één andere variabelen. In dit geval wordt gesproken van multipele (multivariate) regressieanalyse. Als er een regressielijn opgesteld zou moeten worden, dan zou de volgende algemene formule van toepassing zijn:
y = a + b1x1 + b2x2 + b3x3 + ………. + bzxz
waarbij:
y = afhankelijke variabele
a = intercept
b1 tot bz = de richting en kracht van de variabele
x1 tot xz = de onafhankelijke / voorspellende variabele
De aanpak om te bepalen óf er sprake is van een verband tussen de variabele Y en één of meer van de X'en blijft hetzelfde. In het onderstaande voorbeeld is te zien dat de de variabele x1 wél van invloed is op y, maar dat er geen statistisch significant verband is tussen variabele x2 en Y.
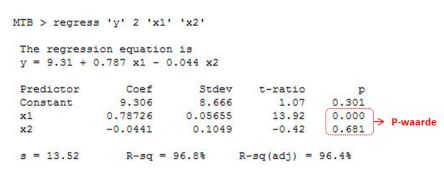
Zoals gezegd is de determinatiecoëfficiënt (R-sq) een maat voor het deel van de variabiliteit dat wordt verklaard door het statistisch model. Er is geen consensus over de exacte definitie van R-sq. Alleen in het geval van lineaire regressie zijn alle definities equivalent. In geval van enkelvoudige lineare regressie is R-sq simpelweg gelijk aan het kwadraat van een correlatiecoëfficiënt. Bij multipel regressie-analyse blijft de R-sq een indicatie van de proportie verklaarde variantie van het regressiemodel, maar is het lastiger dit praktisch te interpreteren.
Bron: The Certified Six Sigma Black Belt Handbook, T. M. Kubiak,Donald W. Benbow
Laatst aangepast op donderdag, 21 december 2017 20:39
LSS: Lean Thinking
Gepubliceerd in
Lean Six Sigma

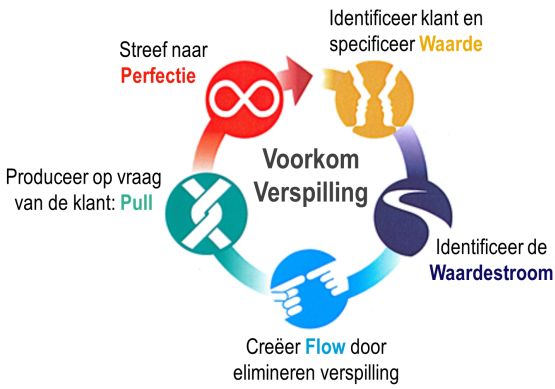
Lean Thinking staat voor de basisfilosofie van Lean die neerkomt op een vijf-stappenplan voor het elimineren van verspillen en versnellen van het proces:
-
Identificeer klant en specificeer waarde: het is de klant, en alleen de klant, die de waarde van het product en de dienst definieert en bepaalt. De klant bepaalt of hij voor een processtap wil betalen of niet. Bij analyse blijkt vaak dat er veel stappen zijn die voor de klant geen waarde toevoegen en waarvoor hij niet wil betalen ('Non-Value Add'-stappen). Deze stappen zijn niet altijd te verwijderen, omdat sommige stappen - van overheidswege of certificerende instanties - verplicht zijn (Necessary but non-value added; NNVA) of nodig zijn om het product of de dienst te kunnen leveren (Value-Enabling).
-
Identificeer de waardestroom: het concept van de waardestroom (value stream) wordt binnen Lean gebruikt om alle activiteiten te beschrijven die worden uitgevoerd om een bepaald product of een bepaalde dienst te kunnen produceren en leveren. Na het identificeren van wat de klant beschouwt als onderdelen die waarde toevoegen aan het proces, kun je via Value Stream Mapping grafisch inzichtelijke maken hoe de goederen- en informatiestromen door de organisatie stromen, waar de waarde stroomt en hoe lang de verschillende processtappen (en de wachttijden) duren.
-
Creëer flow door elimineren verspilling: De ideale toestand van de waardestroom is een constante stuksgewijze flow in alle processen zonder opstoppingen. Flow zorgt ervoor dat het systeem op de juiste snelheid blijft bewegen om de juiste hoeveelheid op het juiste moment aan de klant te leveren. Voor het creëren van flow analyseer je de met de VSM in kaart gebrachte mogelijke bronnen van verspilling en probeert deze vervolgens te verwijderen.
-
Produceer op vraag van de klant ('pull'): het pull-mechanisme (waarbij je goederen en diensten door de processtappen 'trekt') de meest efficiënte manier is om te produceren.
-
Streef naar perfectie: blijf voortdurend verbeteren door de stappen 1 t/m 4 te blijven herhalen.
Zie ook:
Laatst aangepast op donderdag, 02 januari 2020 21:10
LSS: Process Cycle Efficiency (PCE)
Gepubliceerd in
Lean Six Sigma

Binnen Lean (Six Sigma) wordt de efficiciency van een proces uitgedrukt in termen van dat deel van de procesdoorlooptijd die je daadwerkelijk gebruikt om waarde toe te voegen voor de klant.
Stel dat in het onderstaande voorbeeld een proces bestaat uit vijf processtappen (p1 t/m p5). Tussen stap 4 en 5 is sprake van wachttijd. Alleen stap 2 voegt waarde toe voor de klant en gaat nooit fout. Stap 5 is een eindcontrole die moet plaatsvinden op grond van wettelijke regels. De totale doorlooptijd is 70 minuten.
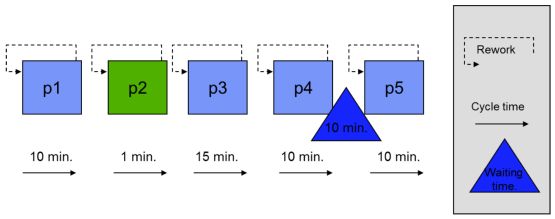
De PCE is te berekenen door de 1 minuut van de waardetoevoegende 2e stap te delen door de totale doorlooptijd van het proces en dit uit te drukken in een percentage: 1/70 x 100% = 1,4%
Laatst aangepast op donderdag, 21 december 2017 20:41
LSS: Process Lead Time (PLT)
Gepubliceerd in
Lean Six Sigma
 wip exit rate.jpg)
Binnen Lean Six Sigma staat de Process Lead Time (PLT), procesdoorlooptijd, voor de tijd die verstrijkt tussen het in het proces komen van een product en het voltooien van dat product. Het gaat dus om de de totale doorlooptijd tussen het moment waarop het verzoek om een bepaald product of dienst te leveren (de order) binnenkomt en het moment waarop de bestelde goederen de productieafdeling verlaten.
Laatst aangepast op zondag, 31 december 2017 07:49
LSS: Procescapabiliteit (Cp en Cpk)
Gepubliceerd in
Lean Six Sigma
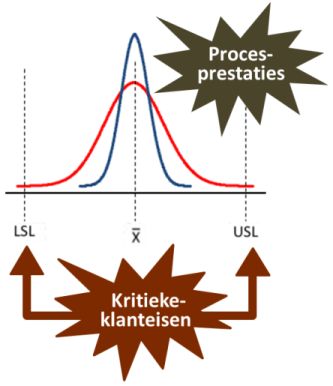
Bij het beoordelen van de procesprestaties kijk je altijd eerst naar hoe stabiel een proces is, waarbij je een regelkaart (control chart) gebruikt voor het beoordelen van de stabiliteit van het voortbrengingsproces. Bij deze beoordeling vergelijk je de procesprestaties met de regelgrenzen (control limits, controlelimieten). Om te beoordelen hoe goed het stabiele proces is, vergelijk je de procesprestaties met de specificatielimieten - ook wel de tolerantiegrenzen genoemd - die horen bij de kritieke klanteisen (CTQ's). Een proces is 'capabel' als het voldoet aan de specificaties van de klant!
Bij de vergelijking tussen procesprestaties en specificatielimieten kun je een aantal kengetallen berekenen, de zogenaamde procescapabiliteitsindices (er is eigenlijk geen goede vertaling voor de Engelse term process capability, maar ik vind 'process capability'-indices zo beroerd klinken, BS). Deze indices geven aan in welke mate het productieproces capabel is de gegeven specificatiegrenzen te garanderen.
Er zijn twee varianten van procescapabiliteitsindices: (a) indices die aangeven wat de potentiële procescapabiliteit is, vooral voor eigen gebruik, dus, en (b) (b) indices die aangeven wat de feitelijke procescapabiliteit is, en dus vooral van belang zijn voor de klant. Een belangrijke voorwaarde om de procescapabiliteitsindices te kunnen berekenen, is dat de procesprestaties normaal verdeeld moeten zijn.
De essentie van alle procescapabiliteitsindices is dat de je de feitelijke procesprestaties 'confronteert' met de specificatielimiet(en) die horen bij de kritieke klanteisen (CTQ's). Concreet betekent dit dat je kijkt hoe de (normale) verdeling van de procesprestaties zich verhoudt tot de bovenste en/of onderste specificatielimieten. Omdat een normale verdeling wordt volledig gedefinieerd door het gemiddelde en de standaarddeviatie, zullen deze parameters - in combinatie met de specificatielimiet(en) - ook bijna altijd terugkomen in de berekening van de procescapabiliteitsindices.
In het onderstaande wordt uitgegaan van een situatie van kritieke klanteisen waarbij sprake is van een productspecificatie met een onder- en een bovengrens. In het gebied tussen de ondergrens (Lower Specification Limit, LSL) en de bovengrens (Upper Specification Limit, USL) voldoet een product aan de specificaties (lees: defectvrij). Dit gebied wordt ook wel het technische tolerantiegebied genoemd.
Cp
De procescapabiliteitsindex Cp is het kengetal dat staat voor de verhouding tussen het technische tolerantiegebied en de variatie van het proces, uitgedrukt in zes maal de spreiding.
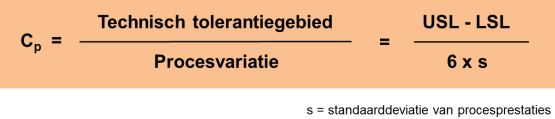
De Cp zegt niets over het werkelijke aantal producten dat buiten de specificatielimiet(en) vallen omdat de verdeling niet precies midden in het technische tolerantiegebied hoeft te liggen. Daarom is voor de klant de feitelijke procescapabiliteit belangrijker. De procescapabiliteitsindex die hier bij hoort is de Cpk.
Cpk
De Cpk is het kengetal dat staat voor de verhouding tussen de afstand van het procesgemiddelde tot de dichtsbijzijnde specificatielimiet en de procesvariatie uitgedrukt in drie maal de spreiding (standaarddeviatie). Wanneer er sprake is van zowel een boven- als een ondergrens, zijn er twee afstanden tussen de specificatielimieten en het gemiddelde te berekenen. Je berekent allebei de afstanden en neemt voor het berekenen van de verhouding de laagste waarde - het minimum - van de twee afstanden.

Hét grote verschil tussen Cp en Cpk is dat Cp géén rekening houdt met de locatie ('centrering') van het proces. Cpk houdt juist wel rekening met hoe de verdeling van de procesprestaties gepositioneerd is ten opzichte van de specificatielimieten. De 'k' binnen Cpk staat voor 'katayori' dat Japans is voor afwijking of verschil. Wanneer het procesgemiddelde precies tussen de specificatielimieten ligt, zijn Cp en Cpk gelijk. Als het gemiddelde niet in het midden van het technische tolerantiegebied ligt, gaan de procescapabiliteitsindices van elkaar verschillen, waarbij Cpk altijd kleiner dan Cp. Cp is de bovengrens voor Cpk. Dit zie je duidelijk terug in de onderstaande voorbeelden:
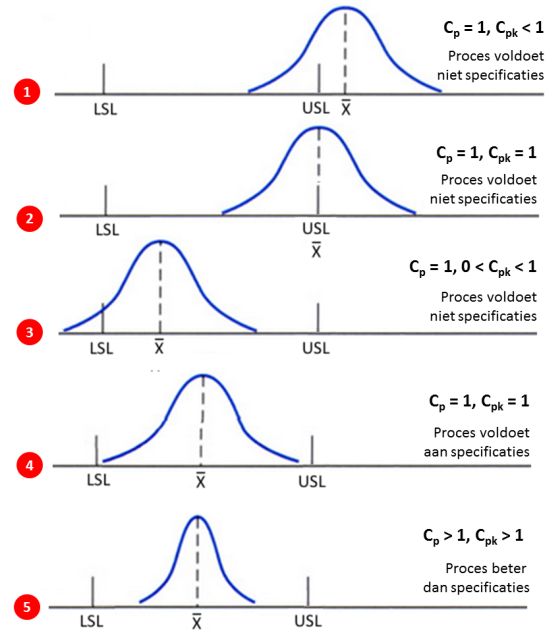
In de bovenstaande voorbeelden, is aangenomen dat bij voorbeeld (1) t/m (4) de totale tolerantiegrens (USL - LSL) dezelfde afstand heeft als zes maal de standaarddeviatie. Dat betekent dat in deze voorbeelden Cp gelijk is aan 1. Afhankelijk van de positie van het gemiddelde en de spreiding van de verdeling van de procesprestaties, verschilt de Cpk-waarde.
In het algemeen geldt, des te hoger de Cp en Cpk waarde, des te beter de procesprestaties. Een vuistregel is dat de Cp-waarde > 1,33 moet zijn.
Bij een Cpk < 1,0 vallen de procesprestaties niet binnen de specificatielimieten; de variatie van het proces valt buiten de tolerantiegrenzen. Een Cpk van 1,0 geeft aan dat de procesvariatie gecentreerd is tussen de specificatielimieten. Als geldt Cpk > 1,0 betekent dat het proces met grote zekerheid voldoet aan de specificaties. Wanneer Cpk gelijk is aan 2 is sprake van een proces op 6 sigmaniveau (3,4 DPMO).
Hieronder nog meer - iets gedetailleerdere - voorbeelden met een beoordeling van het gemiddelde en de spreiding van de procesprestaties:
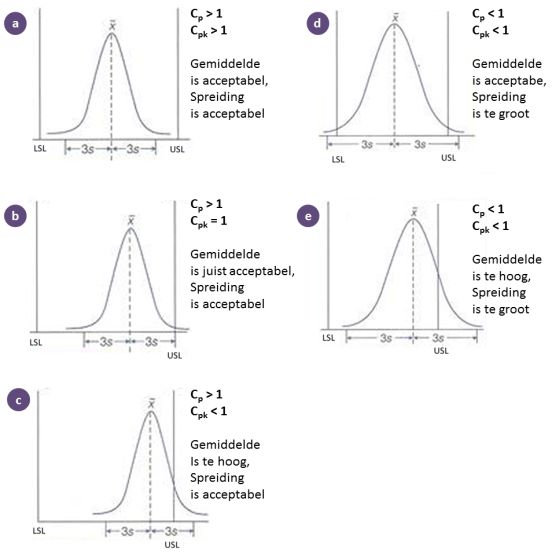
Een hoge Cp-waarde is een noodzakelijke, maar niet afdoende conditie voor een goede sigmawaarde voor een proces. Een hoge sigmawaarde is alleen mogelijk wanneer sprake is van de centrering van het proces gunstig is ten opzichte van de specificatielimieten (herkenbaar aan een goede Cpk-waarde). Om een sigmawaarde van 6 te bereiken (een 'zes Sigma-proces') moet de Cp- en Cpk-waarde gelijk zijn aan 2 (de standaarddevatie past tenminste zes keer tussen het gemiddelde en de specificatielimieten van de klant).
De Cp en Cpk geven de procescapabiliteit aan voor de korte termijn. Als het gaat om de langetermijn worden de waardes uitgedrukt als Pp en Ppk. Gezien het verschil tussen korte en lange termijn wordt bij Cp en Cpk als het gaat om de procesvariatie ook wel gesproken over de 'within variation' en gaat het bij de procesvariatie bij Pp en Ppk dus om de 'overall variation'.
Bij het berekenen van de procescapabiliteitsindices gaat het dus om het bepalen van de verhouding tussen de toelaatbare spreiding (op grond van de specificatielimieten die horen bij de kritieke klanteisen) en de werkelijke spreiding van de resultaten van een proces (procesprestaties). De werkelijke spreiding (procesvariatie) wordt hierbij uitgedrukt in termen van zes keer de standaarddeviatie (6s) en komt dus neer op het verschil tussen plus en min drie keer de de afstand van de standaarddeviatie ten opzichte van het gemiddelde. Dit komt overeen met 99,7% van de procesprestaties. De keuze voor '6s', betekent dat je de Cp ook kan beschouwen als de verhouding tussen de tolerantiegrenzen en het 99,7%-betrouwbaarheidsinterval voor de betreffende procesparameter.
Voor het beoordelen van de procescapabiliteitsindices Cp en Cpk worden de volgende criteria gehanteerd:

Zie ook: LSS: Procescapabiliteit in de garage
Laatst aangepast op donderdag, 21 december 2017 20:38
LSS: Defects Per Opportunity (DPO)
Gepubliceerd in
Lean Six Sigma

Binnen Lean Six Sigma is wordt een opportunity gedefinieerd als elk specifieke kenmerk van een product of dienst dat belangrijk is voor de klant (CTQ) en waarop het product of de dienst een 'defect' (niet voldoen aan de klanteis) of een 'succes' (wel voldoen aan de klanteis) kan 'scoren', de zogenaamde defectmogelijkheid.
De procesprestatieindicator (metriek) Defects per Opportunity geeft aan wat de verhouding is tussen het aantal waargenomen defecten en het aantal defectmogelijkheden. Het aantal waargenomen defecten en defectmogelijkheden kan worden vastgesteld per eenheid, maar ook voor het aantal geïnspecteerde eenheden.
De overeenkomst tussen de DPO en de Defects per Unit (DPU), verhouding tussen het aantal waargenomen defecten en het aantal geïnspecteerde eenheden, is dat beiden het aantal waargenomen defecten als uitgangspunt hebben. Hét verschil is dat bij de DPO dit aantal wordt afgezet tegen het aantal defectmogelijkheden, terwijl bij de DPU de verhouding wordt bepaald ten opzichte van het aantal geïnspecteerde eenheden. De DPU is daarmee minder goed bruikbaar om prestaties tussen verschillende processen met elkaar te vergelijken. Een DPU van 0,4 voor een complex product als auto heeft een andere betekenis dan hetzelfde defectpercentage per eenheid van een relatief eenvoudige fiets. Een auto heeft namelijk veel meer mogelijkheden tot defectmogelijkheden.

Het aantal opportunity's in een eenheid, wat die eenheid ook moge zijn, is een directe maat van haar complexiteit. Sterker nog, als je wilt weten hoe complex een eenheid is, tel je of schat je hoeveel mogelijkheden er zijn op succes of falen. (...) Als je relatieve defectpercentages van systemen met zeer verschillende complexiteit direct wilt vergelijken, zoek je het defectpercentage per opportunity. Deze meeteenheid noemen we defects per opportunity (of DPO).
Berekenen DPO
Een webwinkel onderzoekt de kwaliteit van het proces van het maken van facturen. Op basis van onderzoek is vastgesteld dat de onderstaande zes aspecten belangrijke criteria zijn voor de klanten (CTQ):
- Juist adres
- Juist factuurnummer
- Juiste prijs
- Juist kortingspercentage
- Juiste aantallen
- Juiste datum
Dit betekent dat er zes defectmogelijkheden zijn. Een defectmogelijkheid is elke mogelijkheid per eenheid om een 'defect' op te leveren, dat wil zeggen niet te voldoen aan een aan een voor de klant belangrijke klanteis (CTQ). Over een bepaalde periode, zijn 2.000 facturen gecontroleerd. In totaal zijn 75 fouten gevonden. Het aantal defectmogelijkheden is in dit geval 6 x 2.000 = 12.000.
De DPO is te berekenen door het aantal waargenomen defecten (75) te delen door het aantal defectmogelijkheden (12.000).
DPO = 75/12.000 = 0,00625.
Hierboven werd gesteld dat de DPO ook berekend kan worden door te kijken naar het aantal waargenomen defecten en defectmogelijkheden per eenheid. In dit voorbeeld zijn er 6 defectmogelijkheden per eenheid. Bij de 2.000 geïnspecteerde facturen werd 75 keer niet voldaan aan de gestelde klanteis. Omgerekend per eenheid komt dit neer op 75/2.000 = 0,0375 waargenomen defecten per eenheid.
De DPO is nu te berekenen als: 0,0375/6 = 0,00625.
Bron: Six Sigma voor Dummies, Craig Gygi, Neil DeCarlo en Bruce Williams
Laatst aangepast op zondag, 31 december 2017 07:49
|